The following table shows the update performance of a reservoir sketch. We look at 4 average per-item update times: The first k items when initially filling the reservoir, the next k items when the probability of accepting a new item is > 0.5, any remaining items where the acceptance probability is < 0.5, and the overall average.
| Filling | p(accept)>=0.5 | p(accept)<0.5 | Overall |
|---|---|---|---|
| 24.3ns | 24.8ns | 24.5ns | 24.5ns |
These results were generated with items consisting of Longs k=2^20 and n=2^24, and are the averaged result after 1000 priming iterations (not counted) and an additional 1000 test iterations. Tests were performed on a 2012 MacBook Pro.
We always return sufficient information with our reservoir sample sketches to be able to union reservoirs to obtain a reservoir sample over the combined inputs. Below, we present merge speeds for sketches for several values of k.
| k | Mean (ms) | Stdev (ms) |
|---|---|---|
| 100 | 0.002 | 0.0004 |
| 1000 | 0.018 | 0.0009 |
| 10000 | 0.189 | 0.066 |
| 100000 | 1.846 | 0.232 |
Here, we used an item type of Integer, although the specific type seems to have no impact on performance. Because each reservoir stores a set of Object pointers, we believe this will be true regardless of the object type, subject to memory interactions for item types with large class objects. Each result was again produced with 1000 iterations. Each trial unioned a set of 1000 sketches with a uniform k but filled based on a lognormal distribution around k; some reservoirs had n < k while other reservoirs had moved into sampling mode.
Consistent with reservoir updates, we can see that union speed has a nearly linear relationship with reservoir size.
DataFu is an Apache project that includes a set of Pig UDFs for various data processing purposes. Because the focus of the Sketches library is on sublinear or bounded-size algorithms, compared the performance of our reservoir sampling Pig UDF against DataFu’s basic reservoir sampling, which uses a pre-specified maximum size.
We tested the two Pig UDFs using the same methodology: Generate input data, instantiate the UDF object, and time calls to exec(). Lacking a dedicated Hadoop cluster for proper experimental control, tests were run directly in Java on a local (and rather aged) box. The relative performance was consistent across various values of k so we present k=2048 as a representative example.
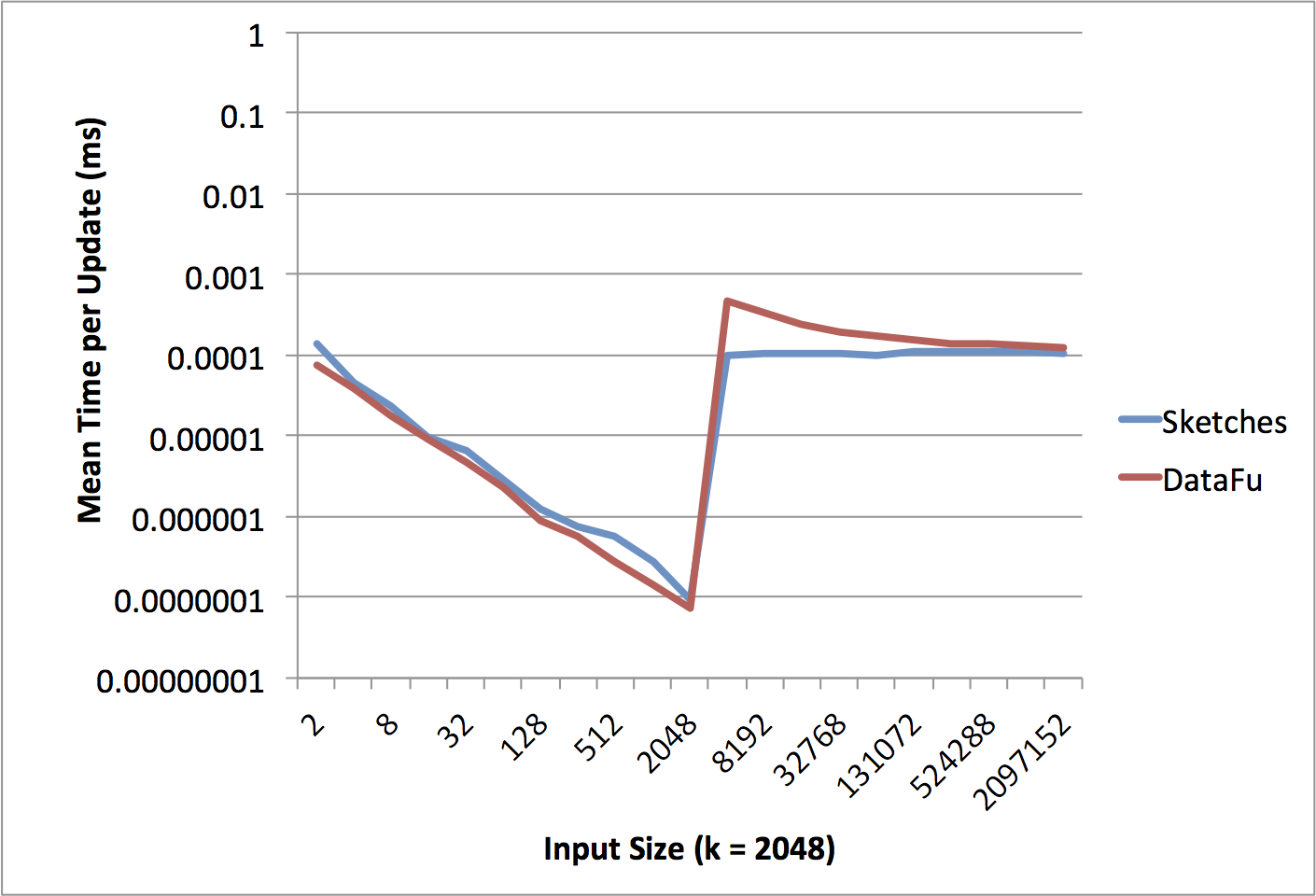
Because the data is input as a Pig DataBag, the UDF knows the input data size when starting processing. If the total input size is less than the maximum reservoir size, the entire input data can be returned, which requires handling only a pointer to the DataBag, which is a constant time independent of the size of the bag. As a result, the time per update decreases with increasing data size until the total input data reaches k. While DataFu returns only the input bag, the Sketches library returns a Tuple of (n, k, samples) to allow for future unioning; the need to allocate a new container explains the time difference between the systems in this time range.
When we must sample data, the Sketches library outperforms DataFu. DataFu’s underlying data is stored as a priority queue, which allows for compact code at the expect of more expensive updates. The performance difference is largest when n is only slightly larger than k, which corresponds to the region in which new items are frequently accepted into the reservoir. With a heap-based implementation, each accepted item incurs an update cost of log(k). As the number of items grows, the cost of processing each data element becomes relatively larger and dominates the total cost, which is why DataFu’s performance starts to asymptote towards that of the Sketches library.
All testing code for these results is available in the sketches-misc repository.

