The primary objective for the Memory Component is to allow high-performance read-write access to Java “off-heap” memory (also referred to as direct, or native memory). However, as documented below, this component has a rich set of other capabilities as well.
The DataSketches memory component has its own repository and is released with its own jars in Maven Central (groupId=org.apache.datasketches, artifactId=datasketches-memory). This document applies to the memory component versions 0.10.0 and after.
To avoid confusion in the documentation the capitalized Memory refers to the code in the Java org.apache.datasketches.memory component, and the uncapitalized memory refers to computer memory in general. There is also a class org.apache.datasketches.memory.Memory that should not be confused with the org.apache.datasketches.memory component. In the text, sometimes Memory refers to the entire component and sometimes to the specific class, but it should be clear from the context.
For compatibility and ease-of-use the Memory API can also be used to manage data structures that are contained in Java on-heap primitive arrays, memory mapped files, or ByteBuffers.
The hardware systems used in big data environments can be quite large approaching a terabyte of RAM and 24 or more CPUs, each of which can manage two threads. Most of that memory is usually dedicated to selected partitions of data, which can even be orders of magnitude larger. How the system designers select the partitions of the data to be in RAM over time is quite complex and varies considerably based on the specific objectives of the systems platform.
In these very large data environments managing how the data gets copied into RAM, when it is considered obsolete, and when it can be written over by newer or different partitions of data, are important aspects of the systems design. Having the JVM manage these large chunks of memory is often problematic. For example, the Java specification requires that a new allocation of memory be cleared before it can be used. When the allocations become large this alone can result in large pauses in a running application, especially if the application does not require that the memory be cleared. Repeated allocation and deallocation of large memory blocks can also cause large garbage collection pauses, which can have major impact on the performance of real-time systems. As a result, it is often the case that the system designers need to manage these large chunks of memory directly.
The JVM has a very sophisticated heap management process and works very well for many general purpose programming tasks. However, for very large systems that have critical latency requirements, utilizing off-heap memory efficiently becomes a requirement.
Java does not permit normal java processes direct access to off-heap memory (except as noted below). Nonetheless, in order to improve performance, many internal Java classes leverage a low-level, restricted class called (unfortunately) “Unsafe”, which does exactly that. The methods of Unsafe are native methods that are initially compiled into C++ code. The JIT compiler replaces this C++ code with assembly language instructions called “intrinsics”, which can be just a single CPU instruction. This results in superior runtime performance that is very close to what could be achieved if the application was written in C++.
The Memory component is essentially an extension of Unsafe and wraps most of the primitive get and put methods and a few specialized methods into a convenient API organized around an allocated block of native memory.
The only “official” alternative available to systems developers is to use the Java ByteBuffer class that also allows access to off-heap memory. However, the ByteBuffer API is extremely limited and contains serious defects in its design and traps that many users of the ByteBuffer class unwittingly fall into, which results in corrupted data. This Memory Component has been designed to be a replacement for the ByteBuffer class.
Using the Memory component cannot be taken lightly, as the systems developer must now be aware of the importance of memory allocation and deallocation and make sure these resources are managed properly. To the extent possible, this Memory Component has been designed leveraging Java’s own AutoCloseable, and Cleaner and also tracks when allocated memory has been freed and provides safety checks against the dreaded “use-after-free” case.
The Memory component is designed around two major types of entities:
The Memory component defines 4 Resources, which at their most basic level can be viewed as a collection of consecutive bytes.
It should be noted at the outset that the off-heap memory and the memory-mapped file resources require special handling with respect to allocation and deallocation. The Memory Component has been designed to access these resources leveraging the Java AutoCloseable interface and the Java internal Cleaner class, which also provides the JVM with mechanisms for tracking overall use of off-heap memory.
The Memory component defines 5 principal APIs for accessing the above resources.
These 5 principal APIs and the four Resources are then multiplexed into 32 API/Resource combinations as follows:
These are the major design goals for the Memory Component.
This includes both package-private classes as well as public classes, but should help the user understand the inner workings of the Memory Component.
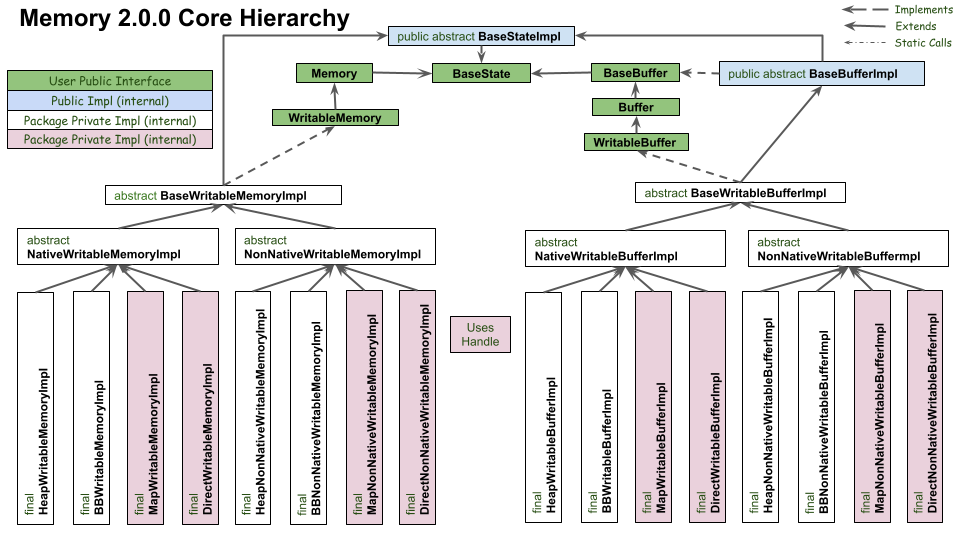
There are two different ways to map a resource to an API.
//use static methods to map a new array of 1024 bytes to the WritableMemory API
WritableMemory wmem = WritableMemory.allocate(1024);
//Or by wrapping an existing primitive array:
byte[] array = new byte[] {1, 0, 0, 0, 2, 0, 0, 0};
Memory mem = Memory.wrap(array);
assert mem.getInt(0) == 1;
assert mem.getInt(4) == 2;
The following illustrates that the underlying structure of the resource is bytes but we can read it as ints, longs, char, or whatever. This is similar to a C UNION, which allows multiple data types to access the underlying bytes. This isn’t allowed in Java! So you have to keep careful track of your own structure and the appropriate byte offsets. For example:
byte[] arr = new byte[16];
WritableMemory wmem = WritableMemory.writableWrap(arr);
wmem.putByte(1, (byte) 1);
int v = wmem.getInt(0);
assert ( v == 256 );
arr[9] = 3; //you can also access the backing array directly
long v2 = wmem.getLong(8);
assert ( v2 == 768L);
Reading and writing multibyte primitives requires an assumption about byte ordering or endianness. The default endianness is ByteOrder.nativeOrder(), which for most CPUs is ByteOrder.LITTLE_ENDIAN. Additional APIs are also available for reading and writing in non-native endianness.
All of the APIs provide a useful toHexString(…) method to assist you in viewing the data in your resources.
Mapping a ByteBuffer resource to the WritableMemory API.
Here we write the WritableBuffer and read from both the ByteBuffer and the WritableBuffer.
@Test
public void simpleBBTest() {
int n = 1024; //longs
byte[] arr = new byte[n * 8];
ByteBuffer bb = ByteBuffer.wrap(arr);
bb.order(ByteOrder.nativeOrder());
WritableBuffer wbuf = WritableBuffer.writableWrap(bb);
for (int i = 0; i < n; i++) { //write to wbuf
wbuf.putLong(i);
}
wbuf.resetPosition();
for (int i = 0; i < n; i++) { //read from wbuf
long v = wbuf.getLong();
assertEquals(v, i);
}
for (int i = 0; i < n; i++) { //read from BB
long v = bb.getLong();
assertEquals(v, i);
}
}
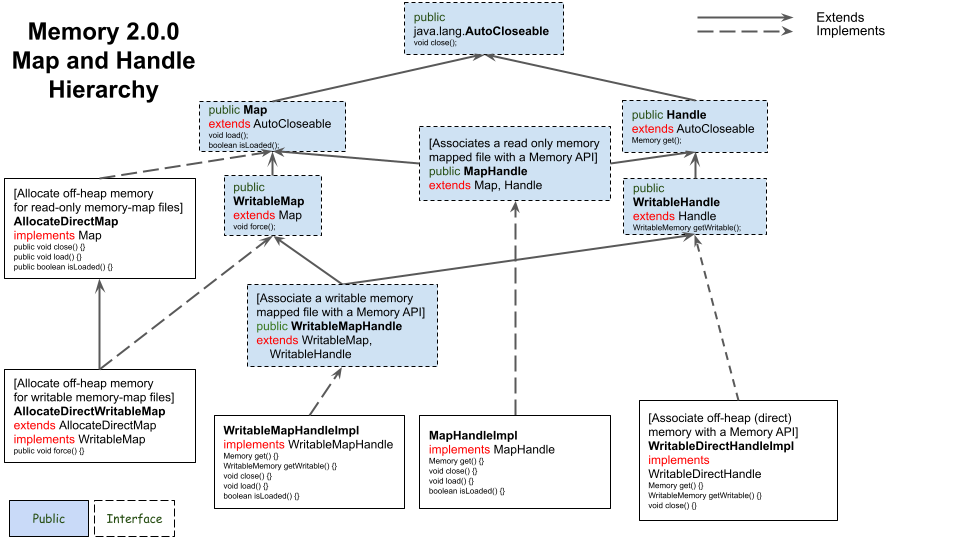
The following diagram illustrates the relationships between the Map and Handle hierarchies. The Map interfaces are not public, nonetheless this should help understand their function.
Direct allocation of off-heap resources requires that the resource be closed when finished. This is accomplished using a WritableDirectHandle that implements the Java AutoCloseable interface. Note that this example leverages the try-with-resources statement to properly close the resource.
@Test
public void simpleAllocateDirect() throws Exception {
int longs = 32;
try (WritableHandle wh = WritableMemory.allocateDirect(longs << 3)) {
WritableMemory wMem1 = wh.getWritable();
for (int i = 0; i<longs; i++) {
wMem1.putLong(i << 3, i);
assertEquals(wMem1.getLong(i << 3), i);
}
}
}
Note that these direct allocations can be larger than 2GB.
Memory-mapped files are resources that also must be closed when finished. This is accomplished using a MapHandle that implements the Java AutoClosable interface. In the src/test/resources directory of the memory-X.Y.Z-test-sources.jar there is a file called GettysburgAddress.txt. Note that this example leverages the try-with-resources statement to properly close the resource. To print out Lincoln’s Gettysburg Address:
@Test
public void simpleMap() throws Exception {
File file = new File(getClass().getClassLoader().getResource("GettysburgAddress.txt").getFile());
try (MapHandle h = Memory.map(file)) {
Memory mem = h.get();
byte[] bytes = new byte[(int)mem.getCapacity()];
mem.getByteArray(0, bytes, 0, bytes.length);
String text = new String(bytes);
System.out.println(text);
}
}
The following test does the following:
@Test
public void copyOffHeapToMemoryMappedFile() throws Exception {
long bytes = 1L << 32; //4GB
long longs = bytes >>> 3;
File file = new File("TestFile.bin");
if (file.exists()) { file.delete(); }
assert file.createNewFile();
assert file.setWritable(true, false);
assert file.isFile();
file.deleteOnExit(); //comment out if you want to examine the file.
try (
WritableMapHandle dstHandle
= WritableMemory.writableMap(file, 0, bytes, ByteOrder.nativeOrder());
WritableHandle srcHandle = WritableMemory.allocateDirect(bytes)) {
WritableMemory dstMem = dstHandle.getWritable();
WritableMemory srcMem = srcHandle.getWritable();
for (long i = 0; i < (longs); i++) {
srcMem.putLong(i << 3, i); //load source with consecutive longs
}
srcMem.copyTo(0, dstMem, 0, srcMem.getCapacity()); //off-heap to off-heap copy
dstHandle.force(); //push any remaining to the file
//check end value
assertEquals(dstMem.getLong((longs - 1L) << 3), longs - 1L);
}
}
Similar to the ByteBuffer slice(), one can create a region or writable region, which is a view into the same underlying resource.
@Test
public void checkRORegions() {
int n = 16;
int n2 = n / 2;
long[] arr = new long[n];
for (int i = 0; i < n; i++) { arr[i] = i; }
Memory mem = Memory.wrap(arr);
Memory reg = mem.region(n2 * 8, n2 * 8);
for (int i = 0; i < n2; i++) {
assertEquals(reg.getLong(i * 8), i + n2);
}
}
See the project README for further instructions on how to use the Datasketches Memory library in your own applications.

